celebrating 20 years of vapourware
I'm currently rearranging things. This is actually the history.
Current activity is at : https://hyperdata.it/hkms/
Hyperdata Knowledge Management System (HKMS) is the current working title of a personal project I've been working on for a long time.
Skip down to 'Components' if you wish to avoid the ramblings of an old man.
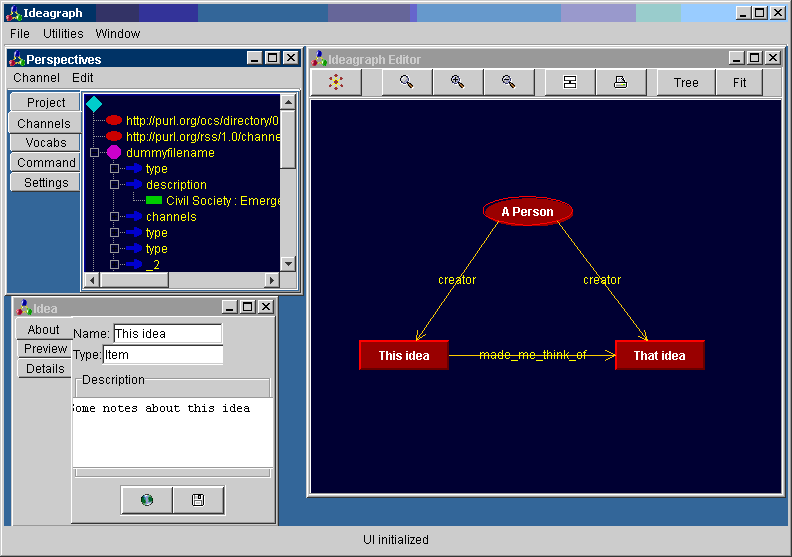
HKMS's first incarnation was Ideagraph, intended as a Personal Knowledge Management System.
Its purpose was :
That might sound like an outrageously wide scope, especially for a lone coder. It was, but it was surprising how far I got in a relatively short period of time as an unexceptional coder. The nearest it got to being finished was the desktop Java app in the screenshot above (other screenshots).
The reason this even remotely possible was that all of these things could share many common components. Critically, they could share the same data model.
A little personal history for context. I'd been interested in AI since seeing 2001 A Space Odyssey as a kid, reading Asimov books. I got into electronics and computing as a teenager. My first computer was a Commodore PET onto which I once typed in a Tick-Tack-Toe AI from a magazine. Years later, at University, I took modules in neural nets and expert systems. Later still, I got online and had a day job at a college that included looking after the network, user support, database admin etc. But it did give me machines to play with
Around 1999 I stumbled upon. This seemed to connect the dots between the interesting AI bits and the Web. At the time I was clueless at both ends, but the rdf-dev mailing list was very friendly, and I gradually picked bits up.
The Resource Description Framework RDF is a set of models and syntaxes for expressing arbitrary data in a form that is natively compatible with the Web. A clue is in the name : Resource in this context is the same as the R in URL. A resource is simply anything that you can identify. A real-world thing, a concept, or more typically on the Web, a document. The neat trick that RDF brings to the table is that you can also identify relationships between things and treat them as resources in their own rights.
Given a model that can identify things and describe relationships between them, you can build networks of information, more commonly known as knowledge graphs. These are versatile enough to be able to express pretty much any can of data you might wish to use on a computer. The practicalities of this can get a bit involved depending on what you're trying to do, but conceptually it's trivial.
Looking back at the list I had for Ideagraph : ideas, projects, blogs, documents... - all things expressible in RDF. Together, standard Java (using Swing for UI) and the nascent Apache Jena framework had all the tools I needed to code something up.
RDF provides a model that can represent pretty much anything. It has various serialization formats so the data can be put in text. But like CSV files, this isn't very user-friendly.
So I wanted to make visualizing and editing RDF a lot more user friendly. In Ideagraph I had three main ways of looking at the RDF:
I can't remember how far I'd got with implementation, but I also had more dedicated views for :
scope drift
too generic
Gradino : RDF-backed blog engine, Java/Scala (retired)
Seki : (retired)
Scute : a Semantic Web hacking tool, desktop Java (retired)
demos : https://hyperdata.it/sparql-diamonds/
link scraper - PWA
markdown
mobile
Bookmark manager : the one in eg. Chrome browser is absolutely hopeless