COLLECTED BY
Organization:
Alexa Crawls
Starting in 1996,
Alexa Internet has been donating their crawl
data to the Internet Archive. Flowing in every day, these data are added to the
Wayback Machine after an embargo period.
this data is currently not publicly accessible.
The Wayback Machine -
https://web.archive.org/web/20021009222134/http://www.isacat.net:80/citnames/2001/04/rpp.htm
S
E M A N T I C I T N A M E S
RDF Process Profile (RPP) Specification 0.0.1
RDF Process Profile (RPP) is a lightweight extensible description format for
processes. RPP is an XML application, conforms to the W3C's RDF Specification
and is extensible via XML-namespace and/or RDF based modularization.
Contents
- Status
- Version
- Introduction
- Terminology
- Vocabulary
5.1 Classes
5.2 Properties
- RDF Schema
- Example
- Notes
- To Do
Mudman in the monsoon season.
Comments should be mailed to danny@panlanka.net
This Version is the latest : http://www.citnames.com/2001/04/rpp-schema.htm
3. Introduction
Metadata is usually defined as being data about data. What is proposed here
is to apply exactly the same techniques to describe processes, moving away
from data-centricity towards a more general resource-centricity. RDF Process
Profile is an attempt to standardize the description of data processors, and
allow their processes to be represented in the same fashion as any other (web)
resource. RPP is intended as a lightweight layer based on RDF(S) which will
allow simple description of a process, on top of which more sophisticated
layers can be built. The processes may be available online, though RPP is
intended to be appropriate for both online and offline resources. To achieve
the maximum applicability of process description wherever possible the processes
will be identified through reference to their algorithm(s), though in practice
it is anticipated that for most processes the algorithms themselves will not
be available, rather an implementation of the algorithm. The goal is to provide
in a RPP document descriptions of all the resources required to carry out
the data processing defined in that document. RPP definitions may be defined
in terms of other RPP definitions, allowing multistage/multilayered process
definition. Terms defined in other schema may be included to extend the functionality
of a RPP document into other domains. The use of a standard metadata format
(RDF/XML) should enable advertising and lookup/discovery of the processes
described in RPP documents. It is hoped that the RPP format will provide a
suitable base layer on top of which other facilities required by online services,
for example process leasing, chain of trust and security management can be
built.
Where a language like DAML allows data to be marked up for agent's consumption,
RPP will describe the agents themselves so they may be fed the right stuff.
It is likely that existing vocabularies contain terms that could be used
in place of those described here. It is believed that in terms of interoperability
that it will be advantageous to encapsulate process-specific metadata in a
single vocabulary, such as RPP. If considered appropriate links to other vocabularies
may be added later in the form of properties such as daml:equivalentTo.
An alternate view of RPP would be that of enabling a meta query system. We
have some data that needs processing or a requirement for data that is specified
in metadata. We supply this to a system containing marshalling facilities
and an inference engine, with access to RPP repositories. The inferencing
required is little more than matching the conventional metadata with an algorithm
described in RPP and then the data and algorithm could be marshalled to an
appropriate processing host and the operation carried out. There may be data
returned from the query but this need not always be the case - e.g. the state
of an external system may be modified.
4. Terminology
4.1 Algorithm
Within this document this word is primarily used in the dictionary sense of
a process or set of rules used for calculation or problem-solving, though
the range of entities described by the term here extend from very abstract
procedures e.g. 'draw a fish' through more canonically expressed forms such
as C source code, also encompassing black box data processors.
The actual detail of the description of an algorithm is in many respects
not significant, as long as there is enough information for an inference engine
receiving a RPP document and a set of metadata to be able to decide (through
reference to external resources as necessary) whether or not the algorithm
described can be realized in a form that can carry out the required processing
of the data the metadata describes.
4.2 Process*
The entities being described by a RPP definition will be referred to as
data processors or processes, with no direct relation to XML processors. Within
this document the terms process and algorithm are used interchangeably, which
is sloppy as in this context they may not refer to the same thing.
Informal prose is suggestive. Formal specification non-lucrative...
5. Vocabulary
RPP follows the conventions for the RDF/XML syntax and model described in
RDFMS. Additional
elements
are as follows :
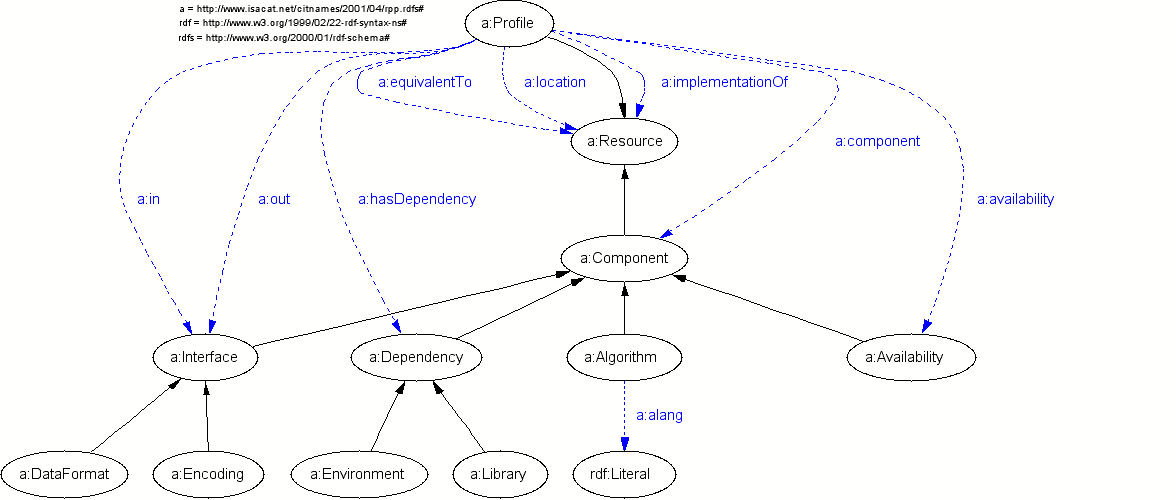
Pretty picture from the wonderful RDFSViz
:
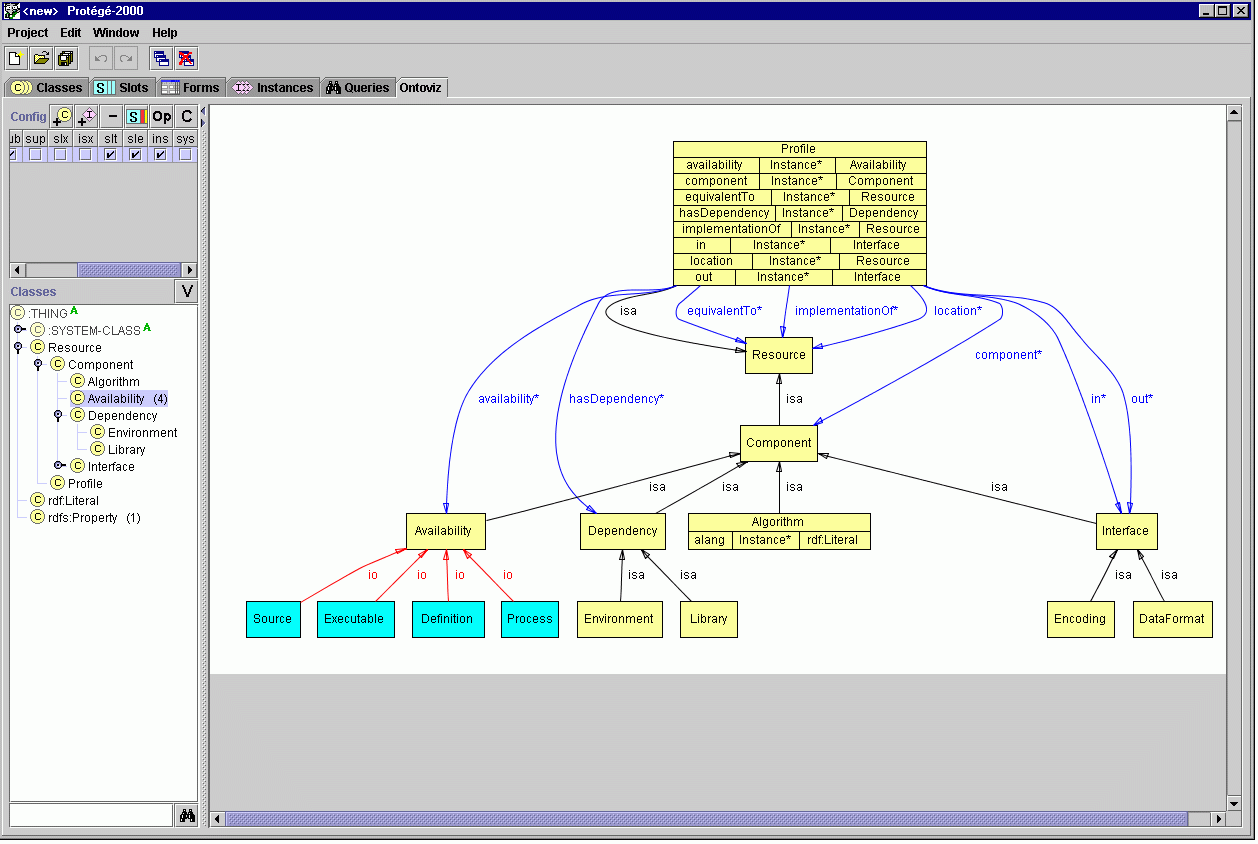
Here's another view of the schema (even prettier
picture!) from Protege using
the
OntoViz plugin (many thanks to Michael Sintek).
// I'm not at all sure about the scoping - my general feeling was that it
would be most useful for the attributes to have there values described by
reference to external documents, though additional local (& literal?)
support might be more appropriate.
5.1 Classes
5.1.1 rpp:Resource
A wrapper around rdfs:Resource to localise references
5.1.2 rpp:Profile
This resource - name and location (not necessarily the same as location
property)
5.1.3 rpp:Component
Container class for classes specifying profile attributes.
5.1.4 rpp:Availability
How machine-friendly the algorithm resource is - one of
definition,
source,
executable or
process. If the resource may be used directly by
sending and/or receiving data as described in the RPP definition, then the availability
property will have the value
process. If the resource may be used
in conjunction with another single (rad:algorithm) resource such as an operating
system runtime environment or interpreter then the availability property will
have the value
executable. If the resource needs more than one
external (rad:algorithm) resource to be able to carry out the required data
processing then the availability will be have the value
source.
If the algorithm is described in a form that isn't machine readable (though
may be human-readable - using any form of notation such as the English language,
diagrams etc) the availability will have the value
definition.
5.1.5 rpp:Dependency
Objects without which the process cannot operate.
5.1.6 rpp:Environment
Particular kind of dependency - runtime environment needed by the executable
algorithm, typically the operating system or virtual machine.
5.1.7 rpp:Library
Particular kind of dependency - typical example would be Java libraries that
had to be on the classpath.
5.1.8 rpp:Algorithm
An identifier for the algorithm of the process - may be name or reference
to source code etc.
5.1.9 rpp:Interface
This will describe the means by which data can pass to and/or from the data
processor. For an online service this might for example be a HTTP POST. For
offline resources this should give adequate description of the data processor's
requirements so that an online data processor meeting these requirements (if
one exists, and is known to the system) may be identified.
5.1.10 rpp:DataFormat
A description of a data format. Typically this will be the URI of a schema.
The schema may be a DTD, XML Schema, human language description or other type.
5.1.11 rpp:Encoding
The low-level encoding of the data to/from the processor
5.2 Properties
5.2.2 rpp:location
The location of the process described by RPP (e.g. the URL to POST to for
online processing or the URL pointing to an executable binary file).
5.2.4 rpp:in
Defines characteristics of the process in its role as a consumer of data.
The domain and range of the data the algorithm consumes will be defined.
A RPP definition of an algorithm can contain any number of input values,
the only constraint being that there is sufficient description to fulfil
the requirements of the rpp:availability property.
5.2.5 rpp:out
As rpp:in, but defines characteristics of the algorithm in its role as
a producer of data.
5.2.6 rpp:alang
Applicable when availability is source or definition. The language the
algorithm is defined in, if known, one of C, C++, Perl, Python, Java, Pseudocode,
UML etc. etc. This may refer to a URI as a unique identifier, or another
RPP document defining the interpreter/compiler.
5.2.7 rpp:hasDependency
Anything required to carry out the process being described.
5.2.8 rpp:implementationOf
A pointer to a more abstract equivalent RPP.
(definition isMoreAbstractThan source isMoreAbstractThan
executable isMoreAbstractThan process)
(isMoreAbstract needs defining? needs inverse?)
5.2.9 rpp:equivalentTo
Any other known versions of the algorithm expressed in RPP format. Typically
this would be used to refer a request for processing on to a more appropriate
processor.
6. Schema
// Big holes - mind your step
This version : http://www.isacat.net/citnames/rpp.rdfs
|
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf = 'http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:rdfs = 'http://www.w3.org/2000/01/rdf-schema#'
xmlns:rpp = 'http://www.citnames.com/2001/04/rpp#'>
<rdfs:Class rdf:ID='Resource'>
<rdfs:label>
RPP Resource
</rdfs:label>
<rdfs:subClassOf rdf:resource='http://www.w3.org/2000/01/rdf-schema#Resource'
/>
<rdfs:comment>
This is a common base class for all resources whose properties may be
asserted in a RDF Process Profile.
</rdfs:comment>
</rdfs:Class>
<rdfs:Class rdf:ID='Profile'>
<rdfs:label>
RPP Resource
</rdfs:label>
<rdfs:subClassOf rdf:resource='#Resource' />
<rdfs:comment>
The Profile itself.
</rdfs:comment>
</rdfs:Class>
<rdfs:Class rdf:ID='Component'>
<rdfs:label>
RPP profile component
</rdfs:label>
<rdfs:subClassOf rdf:resource='#Resource' />
<rdfs:comment>
Base class for groups of profile attribute values.
</rdfs:comment>
</rdfs:Class>
<rdfs:Class rdf:ID="Dependency" rdfs:comment="needed
to run">
<rdfs:subClassOf rdf:resource='#Component' />
</rdfs:Class>
<rdfs:Class rdf:ID="Environment" rdfs:comment="needed
to run">
<rdfs:subClassOf rdf:resource='#Dependency' />
</rdfs:Class>
<rdfs:Class rdf:ID="Library" rdfs:comment="needed
to run">
<rdfs:subClassOf rdf:resource='#Dependency' />
</rdfs:Class>
<rdfs:Class rdf:ID="Algorithm" rdfs:comment="Abstract
algorithm">
<rdfs:subClassOf rdf:resource='#Component' />
</rdfs:Class>
<rdfs:Class rdf:ID="Interface" rdfs:comment="I/O of
processor">
<rdfs:subClassOf rdf:resource='#Component' />
</rdfs:Class>
<rdfs:Class rdf:ID="DataFormat" rdfs:comment="Data
format">
<rdfs:subClassOf rdf:resource='#Interface' />
</rdfs:Class>
<rdfs:Class rdf:ID="Encoding" rdfs:comment="low-level
data encoding">
<rdfs:subClassOf rdf:resource='#Interface' />
</rdfs:Class>
<rdfs:Class rdf:ID="Availability" rdfs:comment="machine-readability">
<rdfs:subClassOf rdf:resource='#Component' />
</rdfs:Class>
<Availability rdf:ID="Process" />
<Availability rdf:ID="Executable" />
<Availability rdf:ID="Source" />
<Availability rdf:ID="Definition" />
<rdfs:Property rdf:ID='component'>
<rdfs:label>
RPP component property
</rdfs:label>
<rdfs:domain rdf:resource='#Profile' />
<rdfs:range rdf:resource='#Component' />
<rdfs:comment>
Indicates a component profile.
</rdfs:comment>
</rdfs:Property>
<rdf:Property rdf:ID="location" rdfs:comment="location
of the algorithm resource">
<rdfs:range rdf:resource="#Resource"/>
<rdfs:domain rdf:resource="#Profile" />
</rdf:Property>
<rdf:Property rdf:ID="availability" rdfs:comment="how
machine readable is the algorithm">
<rdfs:range rdf:resource="#Availability"/>
<rdfs:domain rdf:resource="#Profile" />
</rdf:Property>
<rdf:Property rdf:ID="in" rdfs:comment="details
of data input">
<rdfs:range rdf:resource="#Interface"/>
<rdfs:domain rdf:resource="#Profile" />
</rdf:Property>
<rdf:Property rdf:ID="out" rdfs:comment="details
of data output">
<rdfs:range rdf:resource="#Interface"/>
<rdfs:domain rdf:resource="#Profile" />
</rdf:Property>
<rdf:Property rdf:ID="alang" rdfs:comment="(programming)
language">
<rdfs:range rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Literal"/>
<rdfs:domain rdf:resource="#Algorithm" />
</rdf:Property>
<rdf:Property rdf:ID="hasDependency" rdfs:comment="anything
that's needed">
<rdfs:range rdf:resource="#Dependency"/>
<rdfs:domain rdf:resource="#Profile" />
</rdf:Property>
<rdf:Property rdf:ID="implementationOf" rdfs:comment="another
algorithm that does the same">
<rdfs:range rdf:resource="#Resource"/>
<rdfs:domain rdf:resource="#Profile" />
</rdf:Property>
<rdf:Property rdf:ID="equivalentTo" rdfs:comment="another
algorithm that does the same">
<rdfs:range rdf:resource="#Resource"/>
<rdfs:domain rdf:resource="#Profile" />
</rdf:Property>
</rdf:RDF>
|
7. Example
// I know this is lousy - in terms of syntax & content (and I'm not
even sure about the font), but I thought if I put this in at least it's
a start - any flames I get should help the learning process ;-)
|
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs = "http://www.w3.org/2000/01/rdf-schema#"
xmlns:dc="http://purl.org/dc/elements/1.0/"
xmlns = "http://www.citnames.com/2001/04/rpp#">
<Profile rdf:about="http://www.w3.org/2000/10/swap/cwm.py">
<dc:Title>Closed World Machine</dc:Title>
<dc:Description>
This is an engine which knows a certian amount of stuff and can
manipulate it.
It is a query engine, not an inference engine: that is, it will
apply rules
but won't figure out which ones to apply to prove something.
</dc:Description>
<dc:Creator>TimBL</dc:Creator>
<availability rdf:resource="#source"/>
<in rdf:resource="http://www.w3.org/2000/10/swap/log.n3#"/>
<in rdf:resource="http://www.w3.org/DesignIssues/Notation3.html"/>
<in rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#"/>
<implementationOf rdf:resource="http://www.agfa.com/w3c/euler/"/>
<location rdf:resource="http://www.w3.org/2000/10/swap/cwm.py"/>
<hasDependency rdf:resource="UNIX"/>
<hasDependency rdf:resource="http://www.w3.org/2000/10/swap/notation3.py"/>
<out rdf:resource="http://www.w3.org/DesignIssues/Notation3.html"/>
<out rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#"/>
</Profile>
</rdf:RDF>
|
8. Notes
The general idea here seems reasonable to me - not distinguishing between
the metadata of program and data just seems like updating von Neumann a bit.
The aim mustn't be confused with any kind of formal notations - this isn't
about making rock-solid formalisms, just providing enough info to be able
to use a process.
Detractors may (hopefully) say that RPP is a gross oversimplification - the
goal is to simplify down to the barest minimum needed to do the job.
The first few RPP documents will be the hardest - once a document has been
built to describe e.g. Python, identifying this will be adequate for RPPs
of processes that use Python (rdfs:isDefinedBy).
It'd be nice to have some clear indication of when the end result of a process
is a graphical representation, but I couldn't think of a way without it seeming
overly arbitrary.
The way CC/PP wraps up attributes in a 'Component' object appealed to this
code junky - seems like a good sub-pattern of 'Profile'.
Given that the primary context for RPP is the web it has not been mentioned
here that it would be desirable for it to be possible to create a RPP document
for any given process - e.g. how an egg is boiled. This may be possible with
RPP as defined in this document, however this hasn't been put to the test.
Hopefully the next version of this specification will take this more into
account.
9. To Do
Need to an 'owner' property (for use with agents)
Need to a pointer to documentation - rpp:rtfm ?
DTD for instances
run it by rdf-interest & xml-dev
change my name, buy a mask
&
leave the country (again!)
© 2001 Danny Ayers All rights
reserved.

{kind=link}